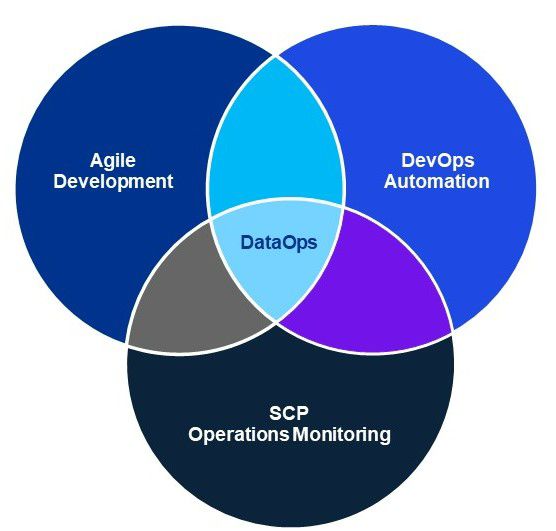
There is no universal definition of DataOps, however, there are several core concepts, the use of the Agile methodology to support the creation of data pipelines, automation of the build cycle using a DevOps toolkit and the adoption of Statistical Process Control techniques to monitor active pipelines.
Agile takes a collaborative approach to development, small cross-functional teams are created with participants, including data technology specialists and business users. Development takes place using short, ‘sprint’ cycles, delivering small pieces of working at rapid intervals. The inclusion of business stakeholders in the team allows the developers to receive frequent feedback and be more responsive and adaptive to changing requirements.
To support short Agile development cycles, DataOps uses automation techniques pioneered by DevOps for integration, deployment, and testing, providing continuous delivery of new features and fixes. The goal of bringing DevOps methods to data engineering is to move away from a world where experts create bespoke data pipelines for each use case, to one of highly automated assembly lines, delivering mass produced pipelines.
By using code to create pipelines and infrastructure you can spin-up new environments as required, creating identical copies of specific set-ups. Our experience at KPMG is that being able to achieve consistency across environments has significant benefits, repeatable testing results across environments, standardized maintenance processes, plus a reduction in troubleshooting effort.
DataOps also looks to improve the stability of operational data pipelines and the quality of data, by adopting Statistical Process Control (SPC) techniques from Lean manufacturing, which was pioneered by the automotive industry, where products must be made quickly and efficiently, while maintaining high quality standards.
The SPC monitoring approach collects metrics relating to data quality and performance at each stage of the pipeline to ensure they are within a normal operating range. If statistical variations occur, the data team can be automatically alerted.
Data Governance is a critical element of an organisations data management, and it should reflect the iterative nature that DataOps brings to the delivery of data. By using the metrics that SPC establishes at each stage of the DataOps workflow it’s possible to apply the principal of continuous improvement to Governance. Every cycle of the DataOps process provides the opportunity for fresh observations of the data and to build those insights into the governance system.