
Why Unstructured Data Matters for AI
AI models are only as good as the data they are trained and run on. Poor-quality, biased, or irrelevant data can lead to inaccurate predictions, flawed decisions, and AI hallucinations. This is especially true for unstructured data, which is rarely cleaned, normalized, or contextualized before being used in AI systems.
Consider these real-world examples:
- A customer service chatbot gives unreliable answers because the training emails were full of inconsistent formats, lacked context, and even contained color-coded tables the AI could not read properly.
- A contract analysis tool mislabels important clauses because the source pdfs had blurry scans, handwritten notes, and sections without clear labels.
These scenarios highlight a critical truth: unstructured data must be clean, representative, and well-governed to support reliable AI outcomes, and this insight also introduces new data quality requirements compared to structured data.
The Shift: From Unstructured to AI-Ready Data
Historically, data management has focused on structured data, which is organized, tabular information stored in relational databases. But the data landscape has changed. Organizations are now shifting toward a broader spectrum that includes semi-structured and unstructured data. At the same time, they are moving away from traditional data management to AI readiness.
AI-ready data is not just stored, it is organized, labeled with the right context, and governed to ensure its quality and security. This is what makes it valuable for AI applications such as language models, image recognition, and generative AI.
The Challenges: What Organizations Are Facing
Managing unstructured data is complex. Our research identifies five key challenges:
- Complexity and scale
The volume and variety of unstructured data – from emails and pdfs to chat recordings and videos – prove to be overwhelming for traditional tools that were designed for structured data. - Lack of context and metadata
Without metadata, lineage, or relationships between data assets, it is nearly impossible to understand how unstructured data fits into the broader organizational knowledge base. For example, AI can also create data and therefore triggers new metadata such as ‘provenance’ to identify whether data was created by AI. - Privacy and compliance risks
Sensitive information often hides in plain sight. Without robust data classification, data labeling and connected access controls and policy enforcement, organizations face significant risks of noncompliance with regulations such as the GDPR and the AI Act. - Organizational and cultural gaps
Many teams are still structured around traditional data workflows and lack the tools, processes, or cross-functional collaboration needed to manage unstructured data effectively. Building AI and data literacy is essential to close this gap and enable teams to manage AI-ready data confidently. - Keep up with the AI pace
Most of today’s AI is focused on task efficiency. However, agentic and autonomous AI will probably require changes to the data governance framework. It is therefore essential to reevaluate this framework to ensure it aligns with the organization’s AI maturity.
An Approach toward AI-Ready Data
As mentioned, initial AI use cases are generally focused on task optimization through summarizing, and, for example, translating data. Therefore, a proper approach must allow for AI use cases to evolve towards agentic and even autonomous AI, resulting in new requirements on AI-ready data. Furthermore, such an approach should be balancing the current (theoretical) frameworks and leverage these where possible – most frameworks will remain relevant for AI models – against the maturity of use cases.
Case in point: a large Dutch financial institution wanted to scale its AI initiatives, but faced a significant hurdle: how to manage the unstructured data within a data governance framework that was solely designed for structured data. For this client, we developed a two-stream approach:
- A workstream with regard to theory and frameworks. Perform an inside-out analysis to identify all relevant policies and frameworks that would be affected by the introduction of AI models and by managing AI-ready data. Subsequently, perform an outside-in analysis by leveraging our available AI-ready frameworks to bring in new guidance, resulting in an overview of required changes and suggested approaches.
- A workstream with regard to use cases. In parallel, we worked hands-on in use cases to identify what was truly needed and to test the practicality of the suggested framework changes from the other workstream. By iteratively implementing solutions and documenting lessons learned, we built up internal ‘case law’, a practical knowledge base that continuously refines the approach, which was translated into a set of ‘AI-ready Data Golden Rules’.
The interaction between both workstreams was crucial for the result; a set of pragmatic Golden Rules for AI-ready data which were incorporated in the ‘AI Way of Working’, ensuring that all (future) use cases reflect on these aspects and further grow AI and data literacy across the organization.
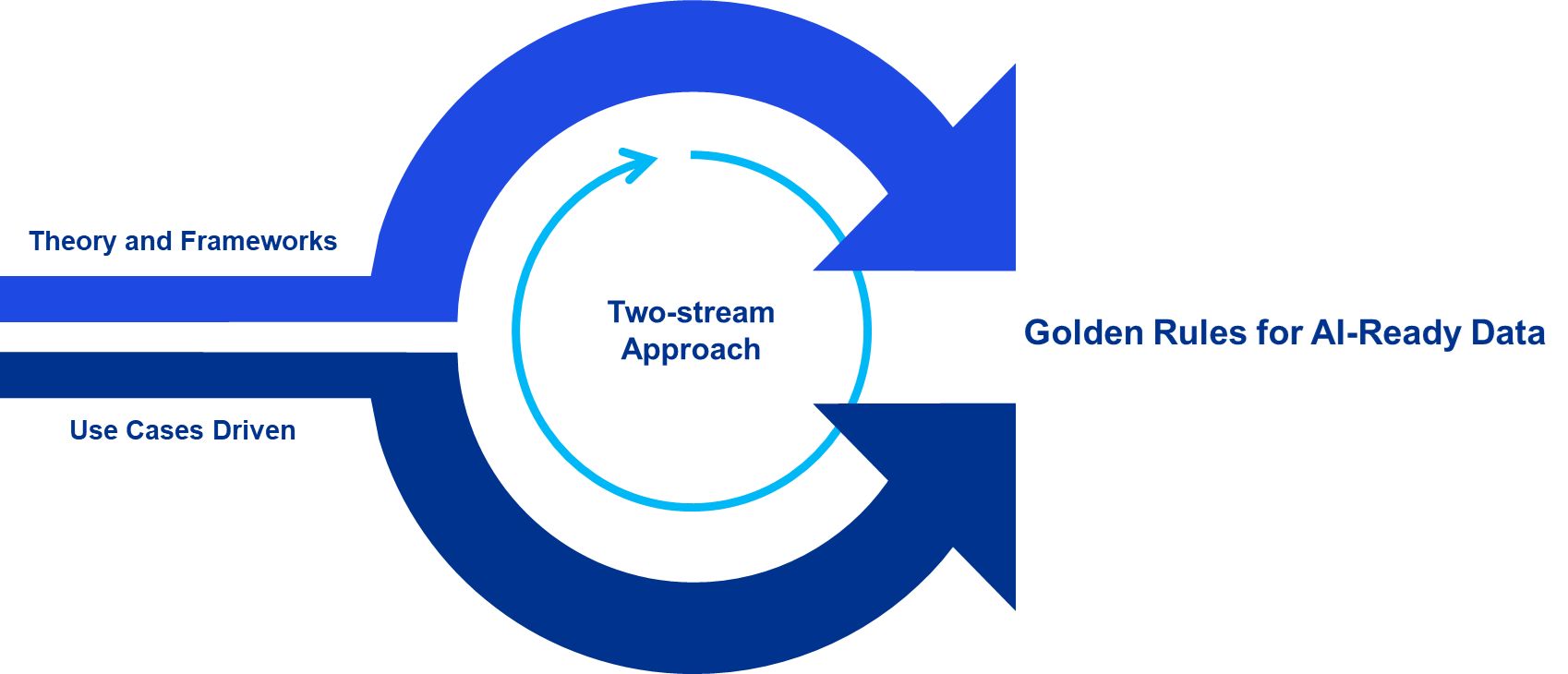
Approach toward Golden Rules for AI-ready data
Clear Results
In addition to the golden rules, the approach also stimulated the cooperation of the Data Management team and the business, and increased the data literacy of colleagues involved in use cases throughout the business domains.
Furthermore, the introduction of ‘case law’ instead of policies gave a balanced approach for the organization in raising awareness for (unstructured) data-related challenges and not adding too much ‘red tape’ that would lower the AI energy.
It also gave the organization a process and structure for periodical recalibration to adjust the Golden Rules to the new AI maturity and to identify potential framework changes in the future.
Why KPMG?
At KPMG, we combine deep expertise in data management and AI technology with a pragmatic, hands-on approach. Our consultants bring experience from across industries and understand the regulatory landscape and know how to translate complex requirements into practical solutions. We do not only highlight challenges, but also bring solutions.
Unstructured data is no longer a blind spot, it is a strategic asset. Organizations that invest in managing it effectively will not only reduce risk but also unlock new opportunities for innovation, efficiency, and growth.
At KPMG, we are here to help you take that next step toward AI readiness, data confidence, and a future built on trust.
