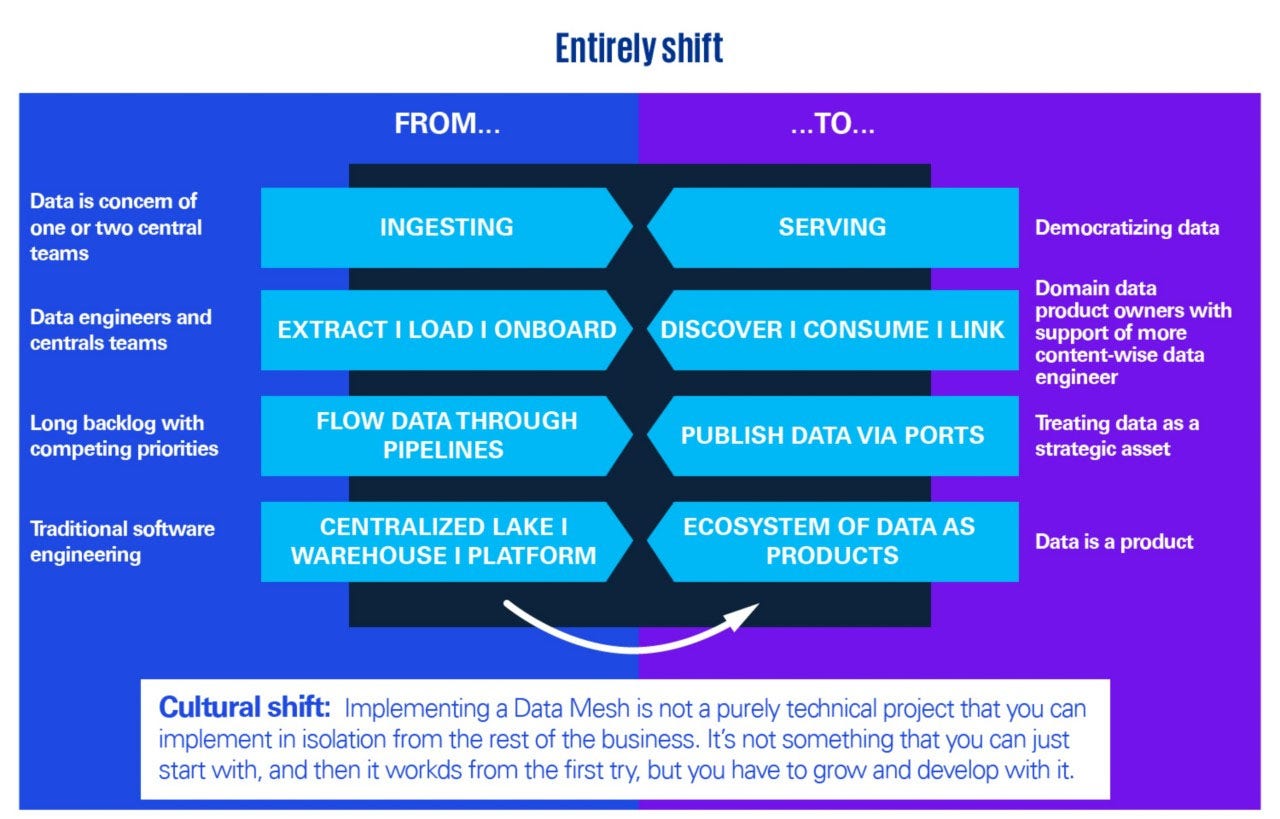
Thanks to data mesh principles, organizations are one step closer to democratizing data and treating data as a strategic asset.
Every day, organizations deal with increasing amounts of data, originating from both inside and outside the organization. Due to centralized data ownership and data access, transparency and timeliness have become bottlenecks in many organizations.
Many companies manage their data like they manage business processes, reports, data models, etc. There might be a central repository of data assets but every business domain uses a very specific subset of those data assets that is relevant to its needs. For instance, we see many finance departments extracting customer data in their own way and interpreting them independently from the sales departments who originally created the data.
Companies invest a lot in this centralized approach. Often there is only one data team in a centrally organized IT infrastructure, which has to manage organization-wide business needs to access, manage, and deliver data to many different stakeholders such as sales, finance, HR, operations, etc. This may lead to disappointment and inefficiencies on both sides, for example:
- The backlog of the data team increases exponentially with the new sources of information and the number of users.
- The business has high expectations of the data team; however, the data team is often not sufficiently aware of the relevant business knowledge, data content, and who uses the data for analytics and decision purposes. This results in several back-and-forth iterations between the data team and the business domains trying to understand the needs of the business while the business expects the highest quality data to be delivered.
The main reason why organizations try to bundle the input of all data sources into one central solution - for example, using a central data warehouse - is to prevent the formation of data silos and to streamline the flow of information.
However, data are often not used to their optimal potential and are mainly used within specific departments by business users who know the context of the data. Business usersstill struggle to manage the data coming from varied sources leading to more requests for the central data team or data engineers. Cross-business domain questions are difficult to answer and reports involving various data sources are not easily developed by business users in a self-service manner.
As an example, account managers often see the value of proactively targeting leads based on a combination of different parameters, such as company size, sector, financial statements, etc. However, their CRM system does not always provide the ability to combine data from different sources to create useful insights. Some requests can be raised to IT and the data team but doing so doesn’t always result in sustainable, user-friendly solutions. Without using organization-wide standardization and governance, this may result in an increased complexity, unused, and invaluable data silos.
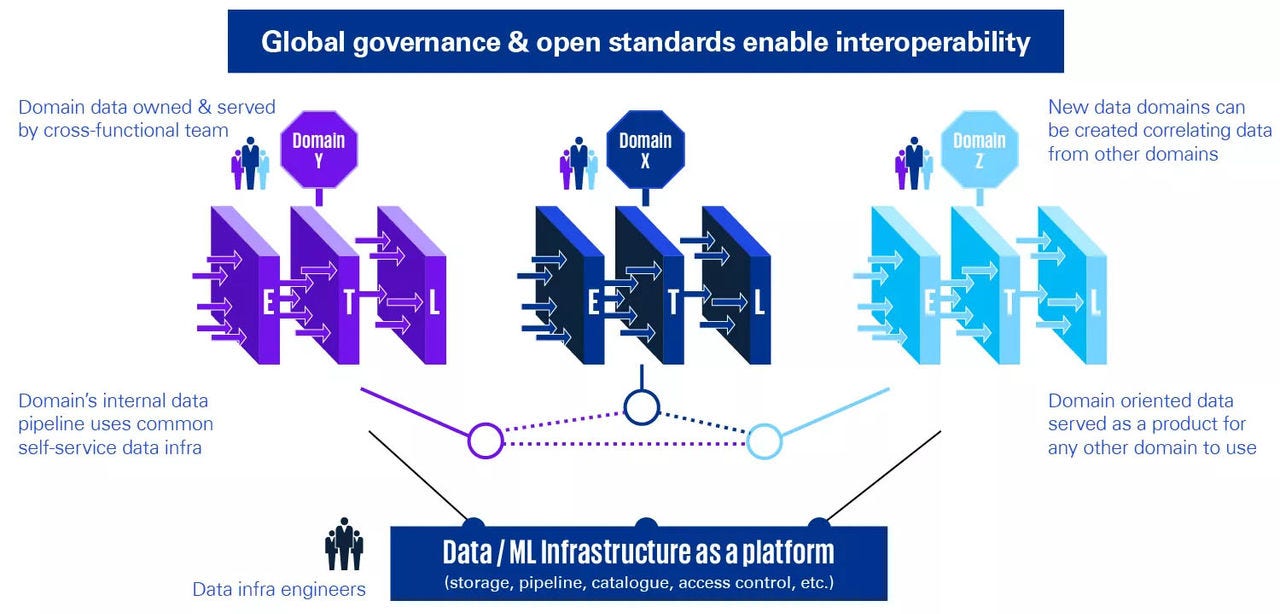
Data mesh aims to eliminate these bottlenecks with a new distributed approach that gives data management and ownership to domain-specific business teams. By decentralizing the ownership of the data per domain, companies can create synergies without having to first break all “data silos”. This can be achieved both by using data for specific purposes and by the domain expertise in the data.
Data and business insights from the data can support business outcomes only when meaningful data are made available to every data consumer.Data needs to be usable by every employee. Data have been recognized by businesses as an outcome-driving asset.
Is data mesh a new trend or a view on data architecture that is likely to stay?
Data mesh is a novel approach based on a modern, distributed architecture for BI (Business Intelligence), analytics, and data management. The main objective of data mesh is to eliminate the challenges related to data availability and accessibility at scale but also to data transformation and reusability. Data mesh is about:
- A decentralized strategy that distributes data ownership to domain-specific teams that manage, own, and serve the data as a product.
- Making data accessible, available, discoverable, secure, and interoperable.
- Enabling end-users to easily access and query data where it lives without first transporting it to a data lake or data warehouse.
- Making data consumable by every employee in the organization, not just the data savvy people, data specialists, or IT experts. The value is in getting data into the hands of the relevant data users.
Data mesh allows business users and data scientists to access, analyze data, and operationalize business insights from any data source, in any location, without intervention from expert data teams. The faster access to query data directly translates into faster time-to-value without needing data transportation.
Data mesh is one step closer to democratizing data and enabling the whole organization to treat data as a strategic asset. This shift introduces a new way of working in many aspects.
“This is where soft values and cultural traits are the biggest factors - making sure to treat data as it should be treated. If you really want to become a data-driven company, data cannot only be a concern for one or two central teams.”
Find out the main principles, the opportunities, and KPMG’s view on data mesh in this blogpost to discover if it is a trend that is likely to stay and whether it could be useful for your organization.